Après une approche très théorique à la branche de l'apprentissage automatique appelée apprentissage supervisé (lire l'article), voici une approche pratique à une autre branche, l'apprentissage par renforcement. Pour cela, je vous propose de jouer à un mini-jeu nommé Hexapawn, une variante des échecs, et d'affronter une intelligence artificielle... toute en papier.
Introduction
À la fin de WarGames, le jeune David et le professeur Falken ont pour mission de désactiver l'intelligence artificielle qui contrôle les armes nucléaires américaines, qui s'est emballée et s'apprête à déclencher une guerre nucléaire mondiale. Ils ne peuvent pas la débrancher, car un système de veille automatique déclencherait alors la mise à feu. Enfin, en dernier recours, ils tentent de « convaincre » l'IA, de lui faire comprendre que la meilleure chose à faire est justement de ne rien faire. Et pour cela, ils vont lui faire jouer au tic-tac-toe contre elle-même, jusqu'à l'épuisement...

Miracle, tout le monde s'en sort, car l'IA a compris la leçon. Après avoir essayé tant et tant, elle n'a pas réussi à gagner. En appliquant cela au « jeu de la guerre », elle se rend compte que le seul moyen pour ne pas perdre, c'est de ne pas jouer. Poétique, n'est-ce pas.
Bien que sorti en 1987, le film fait déjà état de concepts majeurs en intelligence artificielle, notamment l'entraînement et l'apprentissage. Aujourd'hui, nous allons décortiquer quelque peu ces notions, en reproduisant cette expérience (enfin, sans les bombes nucléaires, bien heureusement).
Faire l'expérience à la maison
Matériel
Vous aurez besoin :
- d'un échiquier (si vous n'en avez pas, vous pouvez en imprimer un ou en colorier un),
- de six pions : trois blancs et trois noirs (si vous n'en avez pas, vous pouvez les plier (origami), les imprimer, ou les fabriquer avec des bouchons en liège, des galets, ...),
- de 24 boîtes (des boîtes d'allumettes seraient idéales, mais sinon utilisez des gobelets en
plastiquecarton, ou pliez des boîtes de papier), - d'imprimer cette feuille ; si vous utilisez des boîtes d'allumettes, vous pouvez découper et coller ces imprimés sur les boîtes, sinon, vous pouvez poser vos gobelets sur la feuille,
- de 55 perles de couleurs (si vous n'en avez pas, vous pouvez utiliser des billes, ou imprimer des jetons) ; attention : ces perles correspondent aux flèches de la feuille précédente, il faut que les couleurs correspondent (il y a quatre couleurs, 14 perles pour chaque couleur).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Si vous êtes à l'aise avec l'informatique, vous pouvez choisir vos propres couleurs en utilisant ce fichier : etats.svg. Pour cela, il faut changer la valeur de l'attribut fill de chacun des quatre groupes de flèches. Il faut ouvrir le fichier SVG avec un éditeur de texte (type Bloc-Note), et changer la valeur suivant fill= aux lignes 645, 660, 676 et 692. Les valeurs à inscrire sont des couleurs CSS classiques (RGB, hexadécimal, nom complet, ...).
{kind=link}
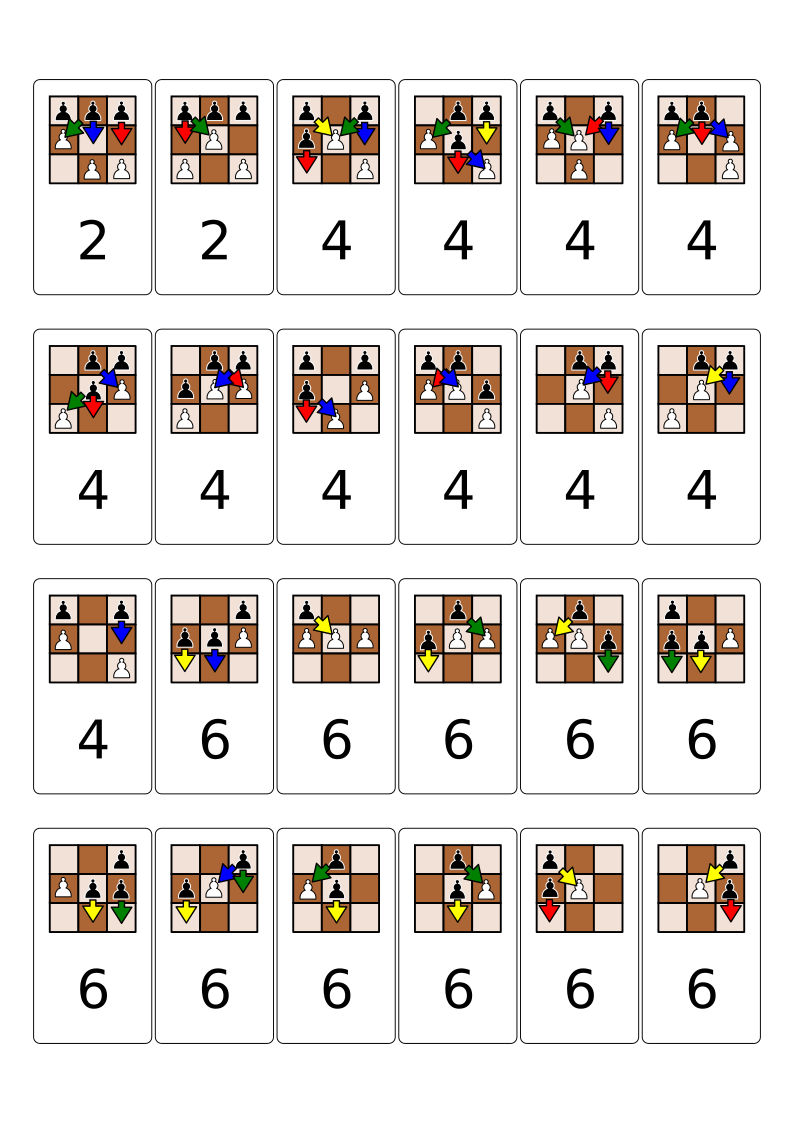
Pour la mise en place, à chaque boîte correspond un état du jeu, ie. un rectangle sur la feuille avec 24 rectangles. Dans chacune de ces boîtes, mettez donc une perle par flèche, en respectant sa couleur. Par exemple : première boîte, trois perles (une rouge, une verte et une bleue) ; deuxième boîte, quatre perles, une de chaque couleur ; etc.
Règles du jeu
Hexapawn est un jeu à deux joueurs, inventé par Martin Gardner. Le nom est formé du préfixe hexa- et du mot anglais pawn, « pion » en français.
Mise en place. Le jeu se joue sur un échiquier de 3 cases sur 3, avec 6 pions, 3 blancs et 3 noirs. Au début de la partie, chaque joueur a ses 3 pions disposés sur chacune des 3 cases de la rangée la plus proche de lui. Comme aux échecs, les blancs commencent.
Déplacement des pions. Les pions se déplacent comme aux échecs (sans la règle du double pas). Ils avancent uniquement en ligne droite, et seulement si la case devant eux est libre. Si une case en diagonale est occupée par un pion adverse, alors on peut également le « manger », en se déplaçant sur cette case et en retirant le pion adverse du jeu.
Conditions de victoire. Un joueur gagne si au moins une des conditions suivantes est remplie :
- il a mangé tous les pions adverses,
- un de ses pions a atteint la rangée de départ des pions adverses,
- son adversaire n'a plus aucun coup à jouer (ses pions sont tous bloqués).
Quelques exemples de parties
| Gain blanc | Gain noir |
|---|---|
L'Intelligence artificielle
Vous jouez avec les pions blancs. Vous commencez donc, et déplacez un pion blanc.
Vient le tour des noirs, donc de l'IA.
L'IA est constituée de boîtes, chaque boîte contenant des perles. Les boîtes correspondent à l'état (la position des pions) actuel du jeu. Il y a 24 boîtes, pour les 24 états accessibles du jeu lors des tours de l'IA (2 états possibles au tour 2, 11 états possibles au tour 4, 10 états possibles au tour 6). L'état est dessiné sur chaque boîte. Pour faire jouer l'IA, commencez par saisir la boîte qui représente l'état actuel du jeu, pour le tour correspondant.
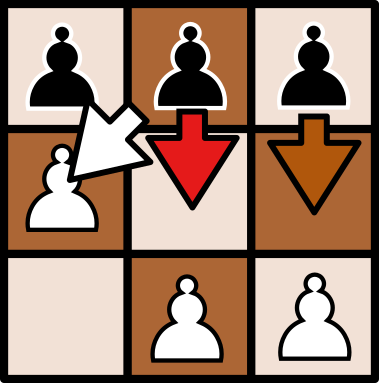
Remarque : si un état semble manquant dans les boîtes disponibles, c'est qu'il faut considérer son symétrique (miroir) par rapport à un axe central. Par exemple, l'état après 1. a2 (on avance le pion blanc tout à gauche d'une case) est le symétrique de l'état après 1. c2. (on avance le pion blanc tout à droite d'une case) :
| État après le coup 1. a2 | État après le coup 1. c2 |
|---|---|
 |
 |
Sur la boîte sont dessinées des flèches, chaque flèche représentant un coup légal de l'IA (donc, avancer un pion sur une case libre ou manger un pion adverse en diagonale). Les flèches sont colorées. À l'intérieur de la boîte se trouvent des perles de couleurs. Initialement, à chaque flèche correspond une perle. Tirez au hasard une perle de la boîte, regardez sa couleur, et jouez le coup ainsi désigné.
L'Apprentissage
Ainsi, lors de la première partie, l'IA ne joue que des coups aléatoires parmi ses coups légaux. L'IA connaît les règles mais n'a aucune idée de comment jouer. En réfléchissant un peu, un humain peut facilement gagner. Mais cela ne va pas durer.
Lorsque vous tirez une perle depuis une boîte, laissez la perle sortie, à côté de la boîte. À la fin de la partie, dans le cas où l'IA a perdu, la dernière perle tirée est retirée du jeu. Puis, remettez les autres perles dans leur boîtes respectives. Si l'IA a gagné, on ne fait que remettre les perles dans leur boîte sans en retirer.
À vous de jouer !
Voilà, tout est prêt, vous pouvez affronter une intelligence artificielle en papier. Vous pouvez faire quelques parties contre un humain pour commencer, pour vous familiariser avec les règles. Puis, jouez contre l'IA. Prenez note de qui gagne chaque partie. Vous devriez commencer par gagner, puis, après une dizaine de partie, l'IA deviendra imbattable.
Quelques explications
À l'instar d'un enfant qui vient de se brûler en mettant sa main dans le feu à qui l'on interdit de jouer avec le feu, on empêche l'IA de rejouer ce coup qui l'a faite perdre. Petit à petit, tous les coups perdants sont ôtés des possibilités de l'IA. Il ne lui restera que des coups gagnants. Le jeu est ainsi fait qu'en jouant parfaitement, le second joueur ne peut pas perdre.
Punitions et récompenses
L'IA apprend via un système de récompenses et de punitions. Dans notre exemple, il s'agit uniquement de punitions. On demande à l'IA de jouer une partie. Si elle perd, on la punit de façon à ce qu'elle ne reproduise plus l'erreur qu'elle a commise pour perdre. À force elle ne commet plus d'erreur.
Nous aurions également pu procéder par récompenses. Lorsque que l'IA gagne, on rajoute une perle de la couleur du coup gagnant dans la dernière boîte. Ainsi, l'IA a plus de chance de reproduire ce coup gagnant plus tard. Notez que les perles des coups perdant restent présentes, il y a donc une petite chance pour que ces coups soient joués même après cent parties. On peut donc cumuler les deux approches : récompenser en rajoutant des perles gagnantes et punir en enlevant les perles perdantes.
En faisant l'expérience, deux phénomènes devraient se produire :
- l'IA commence à gagner plus rapidement,
- l'apprentissage est globalement plus long (l'IA met plus longtemps avant de devenir 100% imbattable).
Le procédé ainsi mit en valeur se nomme l'apprentissage par renforcement (plus connu avec l'anglais reinforcement learning ou RL).
Exploration et exploitation
Ceci est la manifestion d'un problème fondamental de l'apprentissage par renforcement, qui est la balance entre exploration et exploitation. L'exploration représente la capacité de l'IA à tester tout les coups possibles. L'exploitation représente la capacité de l'IA à gagner. L'exploration est suffisante à l'exploitation : si l'on sait à l'avance si chaque coup gagne ou perd, alors il est facile de gagner. Cependant, l'exploration complète nécessite de passer du temps à perdre, pour éliminer les coups perdant. Si l'on souhaite gagner, on doit sacrifier de l'exploration. Ici, cela ne change pas beaucoup, car il est rapide de tout explorer. Mais dans bien des situations, le problème revient souvent à trouver un équilibre entre ces deux aspects.
C'est par exemple le cas aux échecs. On estime à 10^120 le nombre de parties possibles (il faudrait donc jouer longtemps pour tout explorer !). À titre de comparaison, on estime à 10^80 le nombre d'atomes dans l'univers. Pour créer une intelligence artificielle jouant bien aux échecs, il faut lui faire explorer les possibles de façon intelligente. Par exemple, on peut décider d'arrêter d'explorer dès qu'une position est estimée trop perdante : on n'a pas encore perdu, mais on se doute bien que ça ne saurait tarder. On gagne du temps en n'explorant pas toutes les possibles fins à partir de cette position, mais on passe peut-être à côté d'une configuration où nous aurions pu, contre toute attente, gagner. Pour les amateurs d'échecs, un bon exemple est le sacrifice. On perd du matériel, ce qui semble mauvais, mais on peut trouver des contreparties sur le long terme qui vont mener à la victoire.
Définir cette politique d'exploration / exploitation est ainsi déterminant.
Les (désormais moins) récents succès de AlphaGo (pour le jeu de Go) et AlphaZéro (pour le jeu d'échecs) sont ainsi dus (dans une certaine mesure) à l'utilisation d'une technique très performante pour choisir quand explorer et quand exploiter, nommée la recherche arborescente Monte Carlo.
Tic-tac-toe
Nous savons désormais comment faire jouer une intelligence artificielle à Hexapawn, et même résoudre le jeu : l'IA entraînée joue parfaitement, et ne peut que gagner. Seulement voilà, dans WarGames, l'IA ne joue pas à Hexapawn, ni aux échecs, mais au tic-tac-toe. Comme souvent, l'IA que nous avons développée n'est bonne qu'à la résolution d'un unique problème. Nous ne pourrions pas empêcher l'ordinateur de s'emballer, ni la guerre d'éclater. Mais nous ne sommes peut-être pas perdus...
Le jeu Hexapawn et la structure de l'intelligence artificielle pour le résoudre ont été publié par Martin Gardner en 1962 (voir l'article en PDF). Et dans son article, il se base notamment sur le travail de Donald Michie, qui a publié un an plus tôt une méthode similaire pour apprendre à une intelligence artificielle comment jouer au... tic-tac-toe. Avec 300 boîtes d'allumettes. La première expérience (un tournoi IA contre humain) dura 20h pour jouer à la main 220 parties. Être chercheur en informatique dans les années soixantes devait être un drôle de travail. Mais enfin, il arriva à produire une intelligence artificielle capable de battre les joueurs novices et de faire nul contre les joueurs experts.
Deux ans plus tard, en 1963, il s'aida tout de même d'un ordinateur pour simuler cette expérience et l'utiliser plus aisément. Voici l'article qu'il publia pour résumer ses recherches. Nous vous avons préparé une petite démonstration pour re-faire cette expérience vous-même : cliquez ici pour simuler les 300 boîtes d'allumettes qui apprennent à jouer au tic-tac-toe, ou utilisez la fenêtre ci-dessous :
Pour aller plus loin
Les vidéos qui ont inspiré cette démonstration :
- 🎬 The Game That Learns par Vsauce2 (en anglais uniquement)
- 🎬 MENACE: the pile of matchboxes which can learn par Stand-up Maths (en anglais uniquement)
Pour en apprendre plus sur l'apprentissage par renforcement :
- 🎬 Apprentissage par renforcement, une série de 13 vidéos, par Thibault Neveu, pour une présentation scolaire et complète du sujet
À propos d'AlphaGo et AlphaZero, les deux IA développées par DeepMind pour jouer au go et aux échecs :
- 🎬 Jeu de go et intelligence artificielle par ScienceEtonnante
- 🎬 Comment AlphaZero perd ses parties d'échecs ? par Blitzstream, pour une analyse très échiquéenne du comportement d'AlphaZero